|
Zachary Burton |

|
I am a machine learning engineer at Meta working on Facebook Reels ranking. I graduated from MIT, Course XVIII, '26.
My research investigates what LLMs can and can't do in mathematics, and uses those findings to push them toward mathematical superintelligence. Recent work includes diagnosing inference-time mode collapse in RL-trained Lean theorem provers (ICML 2026 AI4Math Workshop), PhD-level expert evaluation for QEDBench at ICML 2026, and RLHF infrastructure for interactive policy personalization (PIEFACE).
I was born in NYC and raised in the UK. Feel free to reach out if you want to chat!
|
Inference-Time Diversity in RL-Trained Lean Theorem Provers: A Diagnostic Study
ICML 2026 AI4Math Workshop (Poster), First Author poster A diagnostic study of inference-time mode collapse in RL-trained Lean provers. Across 3 seeds, V1.5-RL gains +12.3 ± 4.2 theorems under a fixed 15-skeleton schedule while SFT-trained Goedel-Prover loses −10.0 ± 4.4, a 3.7σ asymmetry. A direct distributional measurement (49% of miniF2F gets a deterministic single first-tactic head across 64 stochastic samples) converts “mode collapse” from metaphor to measurement. |
|
|
QEDBench: Quantifying the Alignment Gap in Automated Evaluation of University-Level Mathematical Proofs
ICML 2026 Main Conference (Poster) poster Multi-institution benchmark measuring alignment between LLM judges and human experts on university-level mathematical proofs. PhD-level expert evaluator (probability, discrete mathematics, algorithms). |
|
|
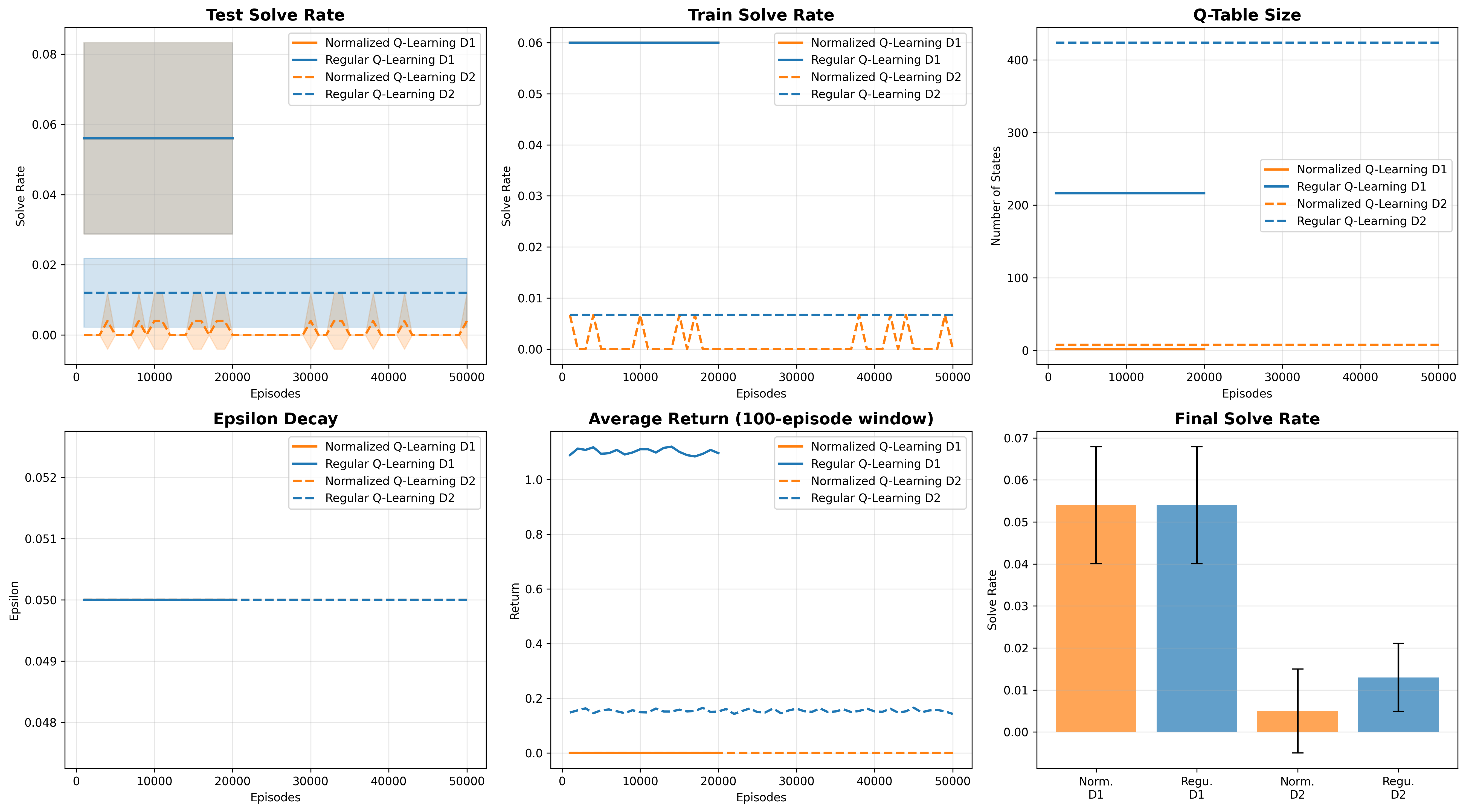
When Does Tabular RL Actually Break?
Blog Post, 2025 post A systematic study of representation bottlenecks in symbolic algebra, testing where RL breaks on high school math. |
|
Collision Thresholds on Lattices
Preprint arXiv An expository derivation using Poissonization and Laplace asymptotics to analyze random walks on lattices. |
|
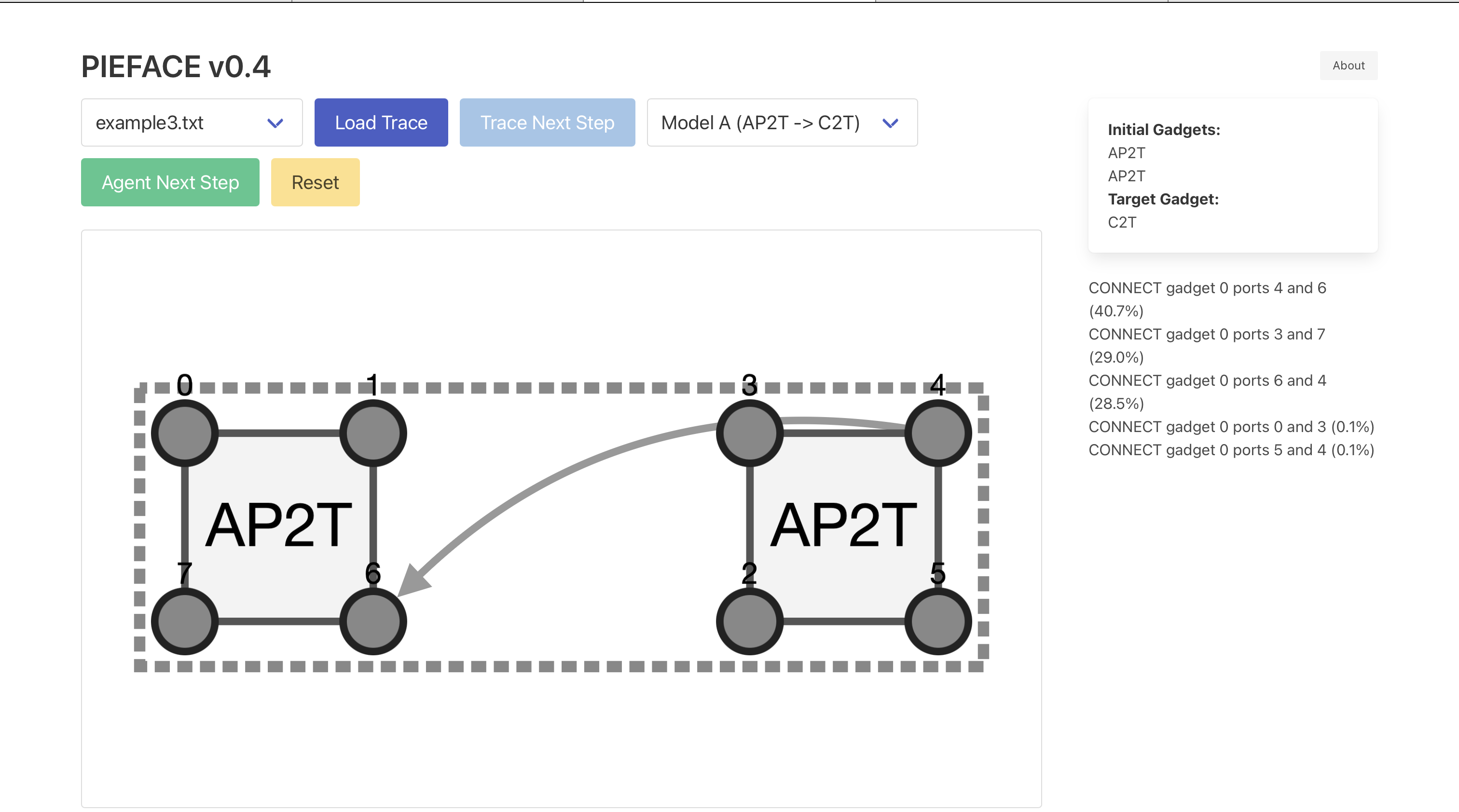
PIEFACE
website Live RLHF platform for interactive policy personalization on an RL agent over motion-planning gadget structures. Flask + SQLAlchemy backend serving Maskable PPO models with top-K action inference over a 217-dim action space, custom PyTorch reward model trained on per-action accept/reject feedback, Cytoscape.js trace visualization frontend. |
|
zOS
github Local LLM self-training loop with step-by-step feedback, written with Rust & Tauri. |
|
Formal Complexity Science
github Autoformalization of classical NP-completeness reductions in Lean 4, built on Mathlib and CSLib. Formalizes Karp reductions (SAT ≤ 3SAT ≤ 3-COLORING, with more planned) as machine-checked proofs. |
|
|
LLM Political Persuasion?
paper 17.279 (Political Misinformation in the Age of Social Media) Final Paper - independent empirical study (n=174, randomized) on AI disclosure effects on belief formation in political conspiracy-framing content. |
|

|
Scribe AI
devpost Autocomplete for math handwriting. |


