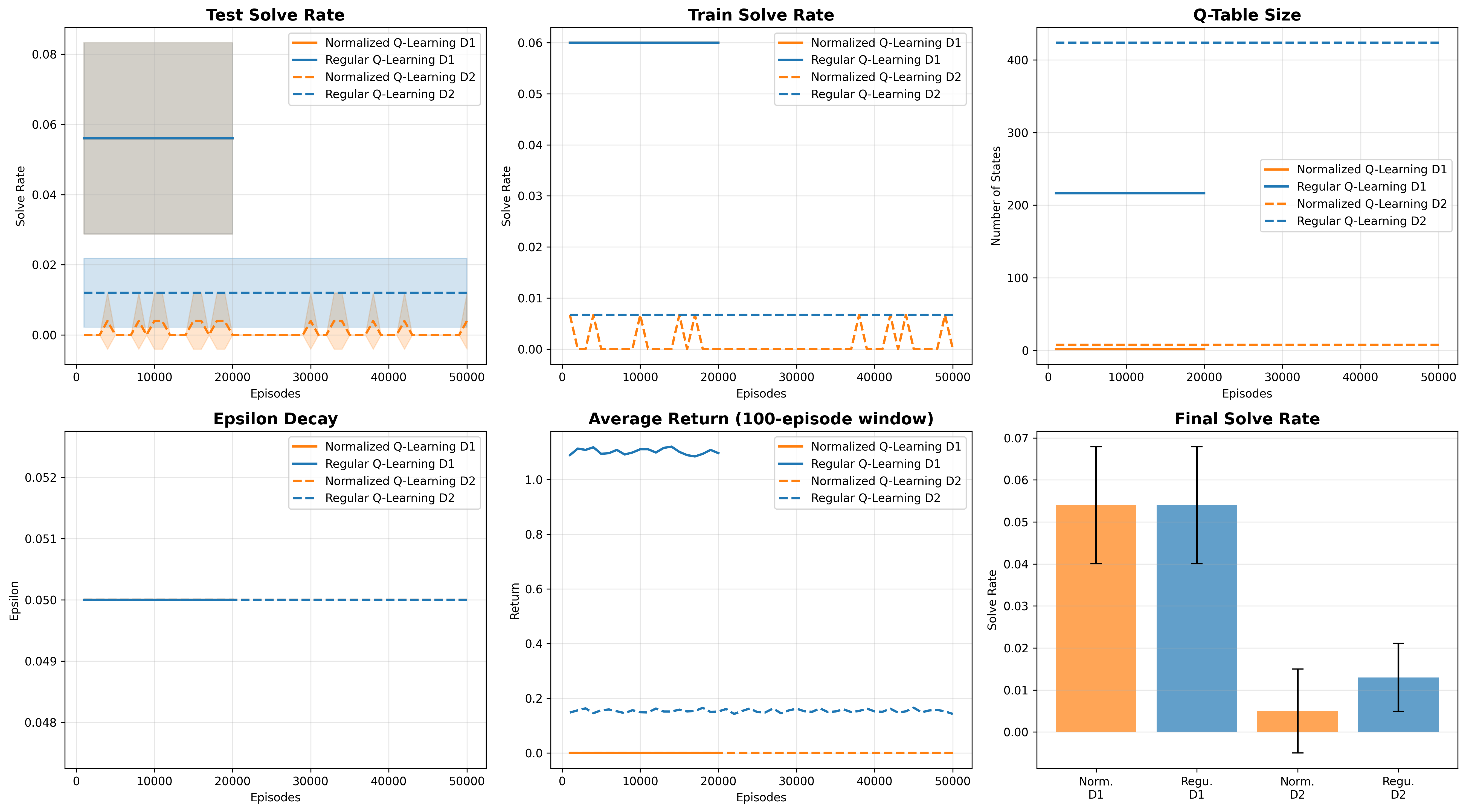
Learning curves over 50K episodes. Both regular and normalized Q-learning plateau at <2% on depth-2.
Testing representation bottlenecks on high school algebra
ax + b = c? We systematically test tabular Q-learning, SARSA, PPO, and neural baselines to find the exact complexity threshold where RL breaks. Spoiler: it's embarrassingly low—depth-2 equations (~8th grade algebra). Even with 50,000 training episodes and neural encoders, solve rates stay below 5%. The problem isn't sample complexity—it's that flat representations can't capture compositional structure.
Modern AI systems like AlphaProof, Harmonic's Aristotle, and AxiomMath's AxiomProver can tackle most International Math Olympiad or Putnam problems alike, with ease. Meanwhile, I wanted to know: what's the simplest math problem where reinforcement learning completely falls apart?
Not because scaling up is impossible (obviously throw enough compute and you can brute-force anything), but because I wanted to understand the fundamental failure modes. Where does the representation break? Is it a data problem or an architecture problem?
So I picked the most trivial symbolic task I could think of: solving single-variable linear equations.
2x = 4 # depth-1: one operation 3x + 5 = 11 # depth-2: two operations 2x - 3 = x + 7 # depth-3: three operations
The task: given an equation, apply algebraic rewrite rules (like "move constant across equality" or "divide both sides by coefficient") until you isolate x.
High schoolers solve depth-3 equations in their sleep. Can RL?
Each equation is represented as an abstract syntax tree (AST). The agent sees the equation as a string (e.g., "Equals(Mul(Const(2), Var(x)), Const(4))") and picks from a set of rewrite rules:
divide_linear: kx = c → x = c/kmove_const_l_to_r: x + b = c → x = c - bcombine_like_terms: ax + bx → (a+b)xEpisodes end when the agent reaches a solved form (x = k) or hits 100 steps. Reward is +1 for solving, 0 otherwise.
I tested four approaches:
All agents use action masking to only select valid rewrites at each step.
I trained each agent for 20,000 episodes on equations of varying depths:
| Agent | Depth-1 | Depth-2 | Depth-3 | Depth-4 |
|---|---|---|---|---|
| PPO | 38% | 19% | 4% | 1% |
| Q-Learning | 4% | 5% | 4% | 1% |
| SARSA | 4% | 5% | 4% | 1% |
| Random | 4% | 5% | 1% | 1% |
PPO does better on depth-1 (38%), but by depth-3 it's back to random performance. And depth-2? A measly 19%.
Why? The obvious hypothesis: state sparsity. Because states are represented as raw strings, "Equals(Mul(Const(2), Var(x)), Const(4))" and "Equals(Mul(Const(3), Var(x)), Const(6))" are treated as completely unrelated—even though they have identical solution structure.
But wait—is this a data problem or a representation problem?
To test this, I ran two follow-up experiments:
What if we explicitly remove the coefficient information? Instead of treating 2x = 4 and 3x = 6 as different states, normalize them both to C·x = C.
This should massively reduce state space. For depth-1 equations, the state space collapses from ~341 unique states down to just 2.
| Method | Depth | Episodes | Solve Rate | Q-Table Size |
|---|---|---|---|---|
| Regular Q-Learning | 1 | 20K | 5.4% ± 1.4% | 341 ± 7 |
| 2 | 50K | 1.3% ± 0.8% | 673 ± 13 | |
| Normalized Q-Learning | 1 | 20K | 5.4% ± 1.4% | 2 ± 0 |
| 2 | 50K | 0.5% ± 1.0% | 8 ± 0 |
Learning curves over 50K episodes. Both regular and normalized Q-learning plateau at <2% on depth-2.
Maybe the problem is that any flat string representation is doomed. What if we let the agent learn its own representation?
| Method | Depth-1 | Depth-2 |
|---|---|---|
| Tabular Q-Learning | 5% | 1% |
| Neural Q-Learning (GRU) | 10% | 4% |
The extended experiments rule out sample complexity. Even with 50,000 training episodes, 99% state space compression, and learned neural representations, agents still can't solve depth-2 equations.
The problem is representations that don't capture compositional structure.
Because ax + b = c requires a sequence of dependent operations:
b to right side → ax = c - ba → x = (c - b)/aA flat string representation can't expose this dependency. The agent has no way to know that "the thing I do now affects what rewrites are possible later."
Based on these results, here's what you'd need to solve even depth-2 equations with RL:
This is exactly what AlphaProof and similar systems do. They don't use vanilla RL—they use heavily structured architectures with symbolic reasoning baked in.
All code is available on GitHub. The experiments ran on Azure ML with H100 GPUs (though most runs were CPU-only). Total compute cost: ~$170 for the extended experiments.